No doubt ! Web 2.0 has been a great turnaround in the history of web computing, technologies like AJAX, RIA, SOA, CSS, Silverlight, Mashups, Web Slices, RSS and XML have been the front runners for this newer version of web. Products and Services like Facebook, Flickr, iTunes, MapQuest, Windows Live, GoogleMaps, Virtual Earth, YouTube, Orkut etc have not been possible without the advent of Web 2.0.

However on the other hand it gives me a feeler that these Internet Applications, Community based websites, Photo Albums, Rich Maps, Blogs and Video based portals just gave the Web a great look and feel on both the application design and performance scales. However, they did not contribute towards the robustness and intelligence of the engine itself.
I am one of those learners of the modern web who claim Web 2.0 to be the “people oriented web” and Semantic Web to be the “machine oriented web”.
During your university coursework, you are convinced with thousands of examples which highlight the importance of the application of data mining, machine learning, software agents, logic based programming, constraint based Programming, P2P and grid computing in our computer program and systems. We all agree on how Machine Learning can find hidden patterns and discovers the facts which would never have come out of the terabytes of the data within an Enterprise. Grid computing can easily share the processing workflow amongst multiple physical machines and saves you cost and time. Software agents deployed on the target machines have the ability to learn and make decisions based upon logical reasoning without the knowledge base. When it comes to the real world application you will definitely find these implementations but in a limited scope and mostly on private systems such as an airline software, medical research tool, analytic software, a robotic solution etc. Hence, here one thing is pretty much clear that we have the concepts in grip and there is an implementation as well but the scope is pretty limited and is segregated.
However the case would have been strong if the scope had not been limited and such implementations would have been the part of the World’s largest and fastest growing network, which resides billions of web pages, targeting millions of users, catering thousands of businesses categories, developed using hundreds of various modern tools and technologies, the Internet. Unfortunately the current structure of the Web is targeted towards the people and focuses on rich, user friendly and robust applications but completely ignores the concepts such as data mining on the Web, which has been the core implementation coming out from the concepts of machine learning, logic based programming and software agents.
The current shape of web is quiet unstructured where it has various of web databases, service engines and representation formats which makes searching and comprehending the web a challenge. For the web to reach its full potential, we need to improve the service engines, develop data structures behind the code, align the data presentation formats, data mining and machine learning techniques are to be applied in order to search and find only the useful and relevant patterns, as only a small portion of web pages contain useful and required information.
In a nutshell, the Internet is the world’s largest data store and after typing your query in a search engine, within fraction of a second you are shown thousands and thousands of results, with no guaranteed reliability and success prediction because we have not laid any design and structure of our web portals and there is no machine level information exposed for web crawlers, on which any logical reasoning can be done. There is also a lack of automatically created directory structures, and semantic based query primitives are yet to be worked on.
Hence data mining on the Internet is a necessary ingredient of an intelligent web which works with logical reasoning’s, automated decision making and brings in more relevancy to search but unfortunately it is nearly impossible with the current version of web which is just a stack of HTML pages.
How the Semantic web would likely work?
1. What are the world’s significant events in the last decade?
2. Dentists available on Tuesday’s in Parklane hospital?
3. Phone Number of KFC’s NYC branch?
Finding such an information in a local database is a game of few queries but what happens when you want to explore the whole web network to find your relevant information, how do you tell the web that KFC is a fast food restaurant and NYC is a place in New York which is a part of America, so kindly bring the phone number of this particular entity?. .. For this you need to have some sort of design and information presentation mechanism on web and that’s what Semantic Web has brought!
Key requirements for your web to be smart enough:
1) Provide information in expressions which can be understood and comprehended by the machine. The engine knows where the information for its use lies and what the format is so that it can be parsed equivalently.
2) Represent the data structures in knowledgeable formats such that when you want to express Area, it will be a sub class of City whose parent will be Country and so on, and assign data attributes to Area such as Name, Area, Population, Geographical Location etc.
3) Introduction of ontologies and Taxonomies such as a Software Developer and Software Engineer both fall on the same horizontal level in a Software house staff’s hierarchy and both report to a Project Manager. Computer can only know this if you present alternate words for the same thing in its knowledge format i.e. build ontologies and express the relationships between the different classes and their objects falling in a the hierarchical or vertical structures.
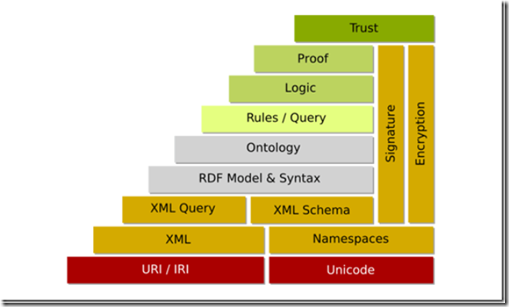
How we can actually achieve the above three requirements and how the presentation of the data and knowledge structures is done on the semantic web, and what tools and technologies come in to action? All this will be covered in the next part of this article. Stay tuned!